
Defines additional terms of the EVA and then explores more deeply the concepts behind the terms.
You should be able to:
+ Describe distributed sparing
+ Describe disk failure protection levels
+ Describe redundant storage sets and their benefits
Distributed sparing
Distributed sparing is the process of using available space in the disk group for several sparing functions. Because the EVA distributes capacity across all members of a disk group, no spare physical disks exist as with conventional arrays. The EVA uses the spare or unassigned capacity on all the disks within the disk
group.
The EVA uses unassigned capacity as needed for items such as:
- Virtually Instantaneous Snapclones (Vsnaps) writes
- New virtual disk creation
- Freeing a physical disk for removal or reassignment
- Data reconstruction after disk failure or disks failures
• for VRAID1 and VRAID5
• VRAID0 data is lost
Data reconstruction
For VRAID5, XCS rebuilds failed (or removed) data on unassigned space using the parity information.
For VRAID1, the data is first copied to unassigned space on different disks from the surviving disk of the mirrored pair. The data is then moved from the surviving disk to the mirrored pairs of the recipient disks.

Disk failure protection levels
Disk failure protection reserves unallocated disk space in a disk group to recover from physical disk failures. Distributed sparing uses free space first; the failure protection level merely reserves free space to ensure it is available for only disk recovery and not for virtual disk creation or Vsnap writes.
You reserve spare capacity by selecting a disk protection level when creating a disk group. The protection level can also be changed after the disk group has been established.
Three disk failure protection levels:
+ None — reserves no physical disk capacity. Instead, unassigned capacity, if available, is used for sparing.
+ Single — reserves enough unassigned spare capacity to recover from a single disk failure. The capacity of two disks must be reserved to recover a single VRAID1 disk if the disk group is full with only VRAID1 Vdisks.
+ Double — reserves enough unassigned spare capacity to recover from a double disk failure. The capacity of four disks must be reserved to recover from a double VRAID1 disk failure if the disk group is full with only VRAID1 Vdisks.
For example, a 36GB disk, when formatted, yields approximately 33.91GB of usable capacity.
Example 1
A disk group of 10 physical disks at 36GB each, with a protection level of None, has a maximum virtual disk size of 338GB.
Example 2
A disk group of 10 physical disks at 36GB each, with a protection level of Single, has a maximum virtual disk size of 270GB (338 – 68).
Example 3
A disk group of 10 physical disks at 36GB each, with a protection level of Double, has a maximum virtual disk size of 202GB (338 – 136).
Redundant storage sets
A redundant storage set (RSS) is a subgrouping of drives within a disk group that reduce the risk of a multidisk failure resulting in the loss of user data.
Virtual disk behavior review
Consider the following behaviors for each VRAID type:
+ VRAID0
• Failure of any disk group member results in a virtual disk failure.
• Unassigned capacity in the disk group does not help you.
+ VRAID1
• Each disk is paired (or married) to another specific disk.
• A disk group with an odd number of disks (for example, a nine-member disk group) would have one unpaired disk. This means one disk would not have any data for the VRAID1 written to it.
• HP recommends that disk groups have an even number of disks.
+ VRAID5
• Data is written in a 4+1 parity scheme.
• Odd or even numbered RSS memberships do not affect the writing scheme.
Disk failures with VRAID1
If a disk group member failure occurs with a VRAID1 virtual disk, and assuming the disk group has spare space allocated or the disk group has enough available free space:
+ Two copies of the failed disk are reconstructed into the free space of the disk group.
• The EVA uses the spare space only if there is insufficient free space.
+ If the unpaired disk were to fail during the reconstruction, the VRAID1 virtual disk would be lost.
+ After the data has been reconstructed, the data is releveled across the remaining members of the disk group.
• The releveling may take hours to complete.
• For odd-numbered disk groups, one disk is not used.
+ If another disk fails (not the unpaired disk) during the releveling:
• With adequate disk group free space or allocated spare space, the reconstruction process would repeat itself.
• Without adequate space or allocated spare space, the failed disk cannot be reconstructed; there is no place to put the reconstructed data.
• Failure of another disk group member only destroys the VRAID1 if it happens to be the unpaired disk of the original lost disk.
When one or more disk group members are added back into the disk group:
- New disk pairings occur.
- RSSs are recalculated.
- Data is releveled across the disk group.
Disk failures with VRAID5
If a disk group member failure occurs with a VRAID5 virtual disk, and the disk group has allocated spare space or enough available free space:
+ Data from the failed disk is reconstructed into the free space.
• The EVA uses the spare space if there is insufficient free space.
• The EVA chooses where to put the reconstructed data based on what will maintain the highest level of redundancy.
+ If another member of the same RSS were to fail during the reconstruction, in most circumstances, the VRAID5 virtual disk would be lost.
+ After the data has been reconstructed,
• RSSs for the disk group are recalculated as necessary.
• The data is releveled across all remaining members of the disk group.
• The leveling may take hours to complete.
+ If during the releveling, another member of the same RSS were to fail:
• With adequate disk group free space or allocated spare space, the reconstruction process would repeat itself.
• Without adequate disk group free space or allocated spare space, a failed disk group member cannot be reconstructed; there is no place to put the reconstructed data.
- RSSs are not recalculated.
+ Failure of another disk group member in another RSS does not disable the VRAID5.
When one or more disk group members are added back into the disk group:
- RSSs are recalculated as necessary.
- Data is releveled across the disk group.
Active-passive failover
Active-passive mode provides active host access to LUNs through one controller. In the event of a failover mechanisms are used to move a LUN from one controller to another. Failover of the LUNs is controlled by either HP StorageWorks Secure Path or by native operating system software.

Active-active failover
Active-active operating mode provides host access to LUNs through both controllers. Active-active is a standard failover protocol for managing multiple path access to data on the EVA4000, EVA6000, EVA8000 and other HP storage products. Active-active enables the use of native multi-pathing software and popular third-party failover applications.
Performance paths
Although LUNs are accessible through both controllers, there are performance differences depending on which path is used. Within the array, each virtual disk is owned by one of the controllers, which provides the most direct path to the virtual disk.
Read I/Os to the owning controller are executed and the data is returned directly to the host. This direct execution reduces overhead, creating an optimal performance path to the virtual disk.
Read I/Os to the non-owning controller must be passed to the owning controller for execution. The data is read and then passed back to the non-owning controller for return to the host. This additional overhead results in a non-optimal performance path.
Because write I/Os always involve both controllers for cache mirroring, write performance will be the same regardless of which controller receives the I/O.
An implicit transfer occurs in one of the following two ways (on two controllers):
• Array detects high percentage of read I/Os processed by the non-owning controller — Maximizes use of the optimal performance path
• Controller fails and the remaining controller automatically assumes ownership of all virtual disks
If a controller fails virtual disk ownership is transferred to the remaining controller and data flows through one controller to all the virtual disks. Virtual disk ownership is transferred to the other controller if approximately 60% of the I/O requests to the data come through the non-owning controller path.
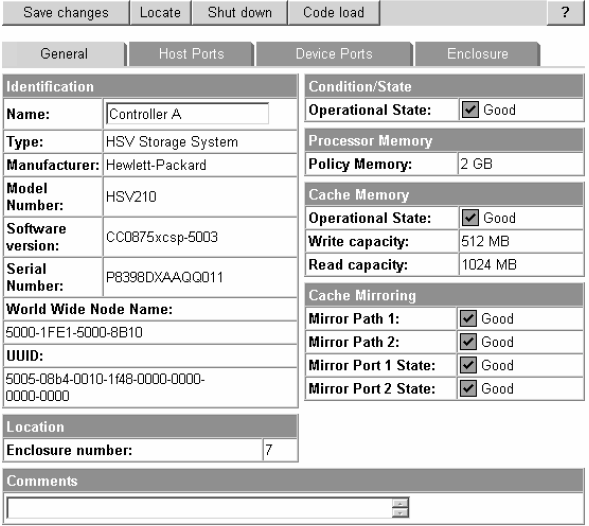
Controller properties
To display the Controller Properties page, select a controller enclosure from a rack folder and then select a controller. The following page displays general properties of the controller such as identification information and status information.
Controller host port properties
The controller Host Ports tab shows the WWN, address (fabric-assigned, 24-bit), operational and connection states, and the speed for each host port.

- 9, for Controller A, host port 1
- 8, for Controller A, host port 2
- B, for Controller B, host port 1
- A, for Controller B, host port 2
The WWN assignments will not change once set.
Controller device port properties
The Device Ports tab shows the following information for each device port:
- WWN
- Loop ID − Arbitrated Loop – Physical Address (AL_PA)
- Loop Position − Sequential loop position
- Operational state for each port

Controller enclosure properties
The Enclosure tab shows information about the controller enclosure—the sealed sheet metal cover that protects the controller circuit board and its associated components.

Disk enclosure properties
A disk enclosure is the physical assembly that contains up to fourteen physical disk drives, an environmental monitoring unit (EMU), power supplies, I/O modules, and blowers.

Disk enclosure bay properties
A vertical disk drive slot in a disk enclosure is called a bay. To display the bay properties, select a disk enclosure and then select a disk bay. This action displays the following page which displays the properties of the slot, not of the drive inserted in the slot.

Disk enclosure Drive properties
To display the properties of the disk drive in the bay, click the Disk Drive tab. Properties such as the following display:

0 comments
Post a Comment