
Objectives
• Name the new snapclone features and functions
• Describe the three-phase snapclone process
• Describe the snapclone replica resynch process
Virtual storage terminology overview
Same terminology as for first generation EVA
• storage system (cell) — an initialized pair of HSV controllers with a minimum of eight physical disk drives
• disk group — a group of physical disks, from which you can create virtual disks
• redundant storage set (RSS) — a subgrouping of drives, usually 6 to 11, within a disk group, to allow failure separation
• virtual disk — a logical disk with certain characteristics, residing in a disk group
• host — a collection of host bus adapters that reside in the same (virtual) server
• logical unit number (LUN) — a virtual disk presented to one or multiple hosts
• virtual disk leveling — distribution of all user data within the virtual disks in a disk group proportionally across all disks within the disk group
• distributed sparing — allocated space per disk group to recover from physical disk failure in that disk group
Physical space allocation
• Physical space allocated the same as for the first generation EVA
• Physical space allocated in 2MB segments (PSEGs)
• Chunk size is 128KB (256 blocks of 512 bytes each), fixed
• One PSEG is equal to 16 chunks (16 X 128KB = 2MB), or 4096 (16 X 256) blocks

Disk groups, virtual disks, and metadata
Same definitions and specifications as first generation EVA
• Disk groups
– Maximum of 16 disk groups per EVA8000, 14 for the EVA6000, and 7 for the EVA4000)
– Maximum number of physical disk drives is the number present in the system up to 240
• Maximum is 56 for the EVA4000
• Maximum is 112 for the EVA6000
• Virtual disks
– Maximum of 1024 virtual disks (first generation EVA was 512)
• Metadata
– Storage system metadata (quorum disks)
– Disk group metadata
Snapshots and snapclones
• Current types for the EVA 3000/5000 series
– Traditional (fully-allocated) snapshots
– Demand-allocated (virtually capacity-free) snapshots
– Virtually instantaneous snapclone
• Improvements for the EVA 4000/6000/8000 series
– Three-phase snapclone
– Snapclone replica resynch (snapclone resynch to source)
– Both improvements require container commands
• Three-phase snapclone requires creation of empty container
• Replica resynch requires a change into an empty container
– Only snapclones can use the containers at present
Container: pre-allocated space used as a receptor of snapclone data.
The layered application called Fast Recovery Solution (FRS) required the new snapclone options called three-phase snapclone and replica resync.
FRS is an HP-supplied solution to provide a non-disruptive backup of a MS Exchange database and a timely recovery in the case of a production database failure. FRS allows the following:
• Ability to create and verify a point in time backup copy of a database while production database is servicing the application
• Ability to recover, in a timely manner, from a database that has been logically corrupted (logical corruption refers to the fact that the database is corrupted, not hardware).
Mechanisms to support FRS also provide the functionality to other user applications.
Three-phase snapclone
Three-phase process
1. Create an empty (pre-allocated) container
2. Cache flush — Write-through mode transition
a. Flush controller cache
b. Set cache from write-back mode to write-through mode
c. Notify host of completion
3. Flick-of-a-switch commit
– Instant association of empty container as snapclone
– Transition source virtual disk to write-back mode
– Up to 10 snapclones at one time
• Note: Once a snapclone is completed, it can be converted to an empty container and re-used

• The first phase represents an active production database, and the pre-allocation of an empty container for later use as a snapclone. This could take place a day or a week before its actual use as a snapclone, but needs to occur far enough in advance for the creation of the empty container to complete and finish its background allocation work.
• The second phase represents transitioning the parent virtual disk to write-through and applications flushing their caches, in preparation for a flick-of-the-switch commit.
• The third phase shows the flick-of-the-switch association of the pre-allocated empty container as a snapclone, and the transitioning of the source virtual disk back to write-back mode. This flick-of-the-switch commit could have happened atomically for multiple snapclones—one per parent virtual disk.
Snapclone replica resynch
• Allows you to revert to a previous point-in-time copy (snapclone) if a virtual disk becomes corrupted
• Allows any virtual disk to be resynched to any virtual disk as long as they match in size, do not participate in sharing relationships, and the target is not presented
• Assumption: you take periodic backup snapclones
• Process includes these steps
– Quiesce the application
– Change the source (corrupted) virtual disk into an empty container
• SET VDISK CHANGE_INTO_CONTAINER command • Creates an empty container with the same settings as the original (corrupted) virtual disk
• Process includes these steps
– Restore the virtual disk data by creating a snapclone of the previously taken backup snapclone
• When the new snapclone completes, it becomes an independent virtual disk with the same settings as the previously corrupted virtual disk
• Data is as current as your most recent backup snapclone
– Restart application on source virtual disk
– Should only be a few minutes of impact
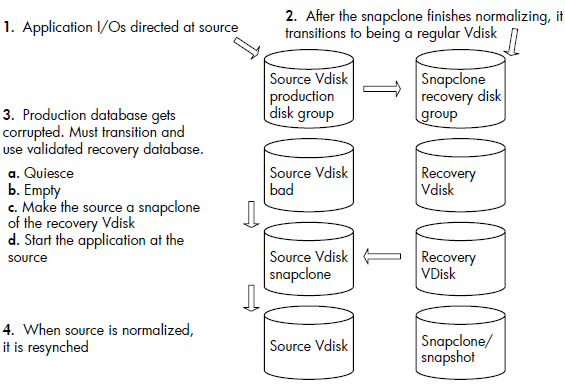
• In the first step, the replication of the production database is shown through a snapclone mechanism.
• In step two, when normalization completes, the recovery database is now its own virtual disk on a separate set of disks. At this point, a validation program is run against the recovery database to make sure it is a clean valid copy, ready to be used as a recovery database.
• The third step shows what happens when the production database fails. The application is quiesced or crashes in response to the logically corrupted database. An empty command is sent to the production database which leaves the storage fully allocated, but empty of data. At this point, the source virtual disk is attached to the recovery virtual disk or database as a snapclone and the application is restarted. This has a number of effects. All of the data in the recovery database can now be read through the production database which is now a snapclone of the recovery database. Writes that come into the production database, if they go to a location in the production database that has not normalized, go through a copy before write, prior to the write completing. In the meantime, background normalization proceeds from the beginning of the recovery virtual disk to the end.
•When it completes, the association of the source virtual disk and the recovery virtual disk is broken, with the recovery virtual disk in the exact same state it was in at the beginning of the recovery. So it is still a valid
recovery database.
• The last step shows the final resynch at the end of the normalization process.
Note: you can do the resynch across disk groups.
Snapclone management
•Command View EVA and SSSU are not the primary platforms to use for three-phase snapclones and replica resynch
• Three-phase snapclone and replica resynch is mainly targeted toward layered applications
– Fast Recovery Solutions
– Data Protector
– Replication Solution Manager
1 comments
Good stuff on EVA-BC
Post a Comment